Table of Contents
Introduction
Artificial Intelligence and machine learning have become integral to modern enterprises. Organizations across industries rely on machine learning models for fraud detection, customer analytics, cybersecurity monitoring, recommendation engines, predictive maintenance, and automated decision-making. While these systems provide tremendous advantages, they also introduce new attack surfaces that traditional cybersecurity frameworks were never designed to address. Among the most dangerous threats emerging in the AI era is data poisoning.
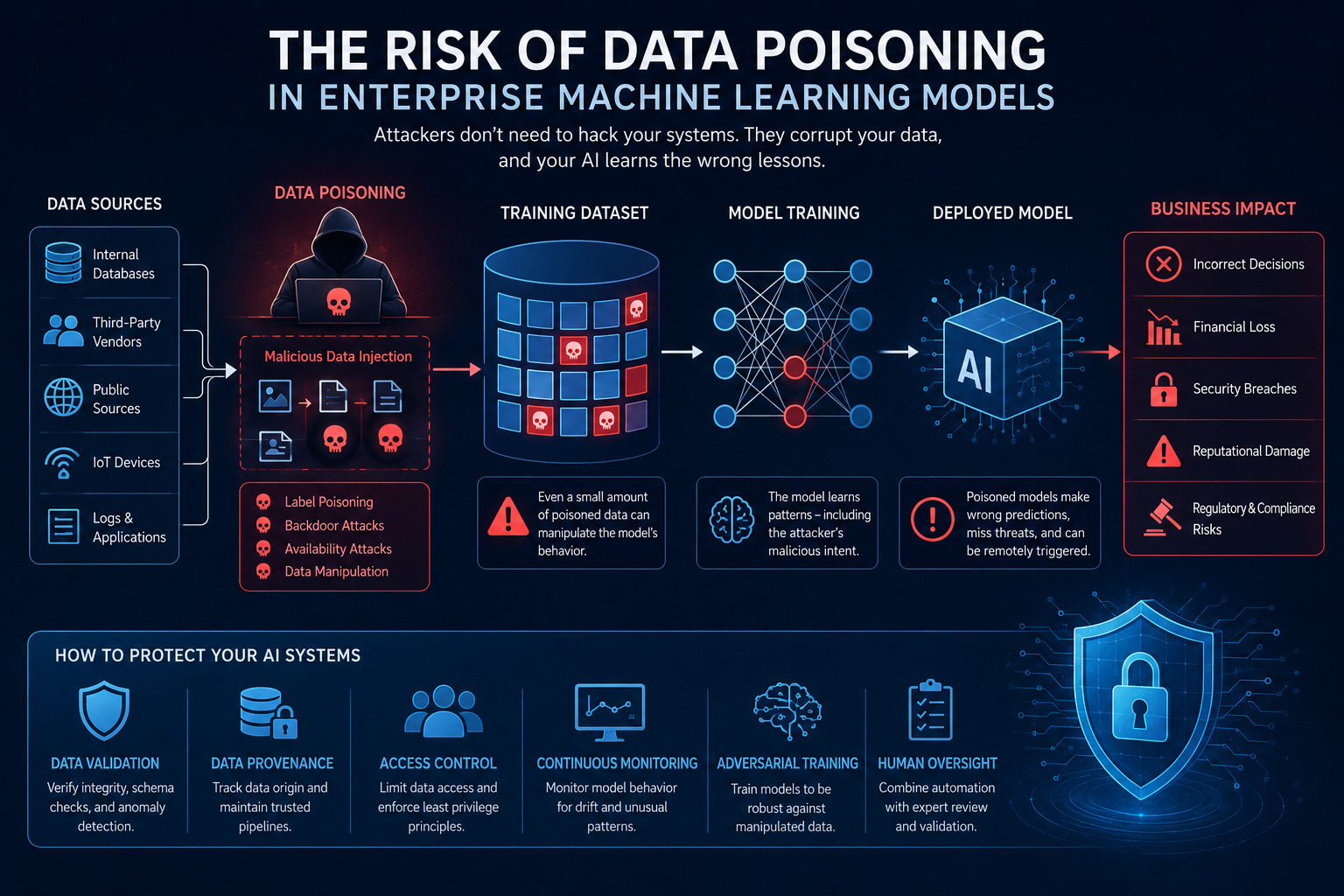
Data poisoning occurs when attackers intentionally manipulate training data to influence the behavior of machine learning models. Instead of attacking software vulnerabilities directly, threat actors target the data itself, corrupting the foundation upon which AI systems learn. Since machine learning models are only as trustworthy as the data used to train them, poisoned datasets can lead to inaccurate predictions, hidden backdoors, security failures, and devastating business consequences.
Unlike conventional cyberattacks that exploit code flaws or network weaknesses, data poisoning attacks exploit trust. Enterprises often aggregate massive volumes of data from multiple sources, including public repositories, customer interactions, IoT devices, third-party vendors, and automated collection systems. If even a small portion of this data becomes compromised, attackers can silently influence AI models without triggering traditional security alarms.
Understanding Data Poisoning
Machine learning systems improve by identifying patterns within datasets. During training, the model analyzes examples and learns relationships that enable future predictions. Data poisoning disrupts this learning process by introducing malicious samples designed to alter those patterns.
An attacker may inject false records into a training dataset, modify labels associated with specific data points, or introduce carefully crafted examples that influence the model’s behavior. Since machine learning algorithms treat the training data as ground truth, poisoned information becomes incorporated into the model’s decision-making process.
The consequences may remain hidden for months. Organizations often discover the problem only after abnormal predictions, inaccurate recommendations, or unexplained failures begin affecting operations.
Why Enterprises Are Attractive Targets
As AI adoption expands, machine learning systems increasingly support critical business functions. Financial institutions use AI for fraud detection, healthcare organizations rely on machine learning for diagnostics, manufacturers employ predictive maintenance algorithms, and cybersecurity companies use AI to identify threats.
Attackers recognize that compromising the training data can provide a powerful and stealthy way to manipulate these systems.
An enterprise AI model that has been poisoned may:
Misclassify malicious activities as normal.
Produce incorrect predictions.
Generate biased outputs.
Fail to detect cyberattacks.
Introduce hidden backdoors.
Damage customer trust and brand reputation.
Because many enterprises retrain their models continuously using fresh datasets, poisoned samples can spread through future model versions, making remediation extremely difficult.
Types of Data Poisoning Attacks
Label Poisoning
Label poisoning occurs when attackers alter the labels associated with training examples. For instance, malware samples may be labeled as harmless files. As the model learns from these manipulated labels, it gradually becomes less effective at recognizing threats.
This attack is especially dangerous for cybersecurity and spam filtering systems because incorrect labels can significantly degrade detection accuracy.
Availability Attacks
Availability attacks aim to reduce the overall performance of a machine learning model. Attackers inject noisy or misleading data into the training set, causing the model to make widespread errors. The goal is not necessarily to gain direct access but to make the AI system unreliable and ineffective.
Organizations relying heavily on automated decision-making may experience operational disruptions, increased costs, and reduced confidence in AI-driven systems.
Backdoor Attacks
Backdoor poisoning is one of the most sophisticated forms of data manipulation. Attackers embed hidden triggers into the training data. Under normal conditions, the model behaves correctly, making the attack difficult to detect.
However, when a specific trigger appears, the model produces attacker-controlled outputs. For example, a facial recognition system may grant unauthorized access whenever a particular pattern is present.
These attacks are particularly concerning because they remain dormant until activated.
Real-World Impact on Enterprises
Imagine a cybersecurity company using machine learning to detect malware. If attackers manage to poison training datasets by introducing malicious files labeled as safe, future versions of the model may ignore genuine malware infections.
Similarly, in financial institutions, poisoned datasets could manipulate fraud detection systems, allowing fraudulent transactions to pass unnoticed.
Healthcare AI systems are also vulnerable. A corrupted dataset could influence diagnostic models, resulting in inaccurate recommendations and potentially affecting patient safety.
Autonomous vehicles, supply chain systems, and recommendation engines face similar risks. Since AI increasingly controls critical business processes, the consequences of compromised models extend beyond financial losses and can affect public safety and customer trust.
How Attackers Introduce Poisoned Data
Modern enterprises gather data from numerous external and internal sources. Attackers exploit these collection mechanisms in various ways.
Crowdsourced datasets represent a common entry point. Public repositories and shared databases may contain manipulated samples contributed by malicious actors. Third-party vendors and external APIs can also unknowingly introduce compromised information.
Insider threats pose another challenge. Employees with access to data pipelines may intentionally or accidentally inject corrupted records.
IoT devices represent additional risks. Compromised sensors can generate misleading information that eventually enters training datasets. Since many organizations rely on automated data ingestion processes, poisoned information may spread throughout the machine learning lifecycle without human review.
Why Detection Is Difficult
Data poisoning attacks are notoriously hard to detect because attackers often manipulate only a tiny fraction of the training dataset. Even a small number of malicious examples can significantly influence model behavior.
Traditional cybersecurity tools focus on malware signatures, network anomalies, and system vulnerabilities. They are not designed to analyze the integrity of training datasets.
Furthermore, machine learning models operate as complex mathematical systems. Identifying exactly which data samples caused unexpected behavior can be extremely challenging. By the time anomalies become visible, multiple generations of models may already have inherited the poisoned patterns.
Strategies to Protect Enterprise AI Systems
Defending against data poisoning requires securing the entire machine learning lifecycle rather than focusing solely on the model itself.
Organizations should implement strict data validation procedures to verify the authenticity and quality of incoming datasets. Monitoring data sources and establishing trusted supply chains help reduce the risk of malicious inputs.
Human oversight remains essential. Experts should periodically review datasets and model outputs to identify unusual behavior. Data provenance mechanisms can trace the origin of information and detect suspicious modifications.
Adversarial training techniques enable models to become more resilient against manipulated inputs. Continuous monitoring and anomaly detection systems can identify unusual shifts in model behavior before significant damage occurs.
Zero Trust principles should also extend to AI pipelines. Every dataset, user, and external source should be treated as potentially untrusted until verified.
The Growing Importance of AI Security
As enterprises accelerate their adoption of artificial intelligence, attackers are shifting their focus from traditional software vulnerabilities toward the machine learning lifecycle. Data poisoning represents a fundamental challenge because it targets the trustworthiness of AI itself.
Organizations that fail to secure their training data risk making decisions based on manipulated intelligence. Since AI systems increasingly influence cybersecurity, finance, healthcare, and critical infrastructure, protecting machine learning models is rapidly becoming a business necessity rather than a technical option.
The future of enterprise AI depends not only on building smarter models but also on ensuring that the data used to train them remains accurate, trustworthy, and resistant to manipulation. In the age of intelligent systems, safeguarding data integrity has become one of the most important pillars of cybersecurity.
Conclusion
Data poisoning attacks demonstrate that machine learning models can be compromised without exploiting a single software vulnerability. By manipulating the data that fuels artificial intelligence, attackers can silently alter predictions, introduce hidden backdoors, and undermine entire business operations. As enterprises continue embracing AI-driven technologies, securing datasets, monitoring model behavior, and implementing AI-specific security practices will be essential for maintaining trust and ensuring reliable decision-making in an increasingly data-driven world.
Frequently Asked Questions
Can data poisoning affect cybersecurity AI systems?
Yes. Attackers can manipulate training datasets to weaken malware detection, spam filters, and intrusion detection systems, allowing malicious activities to bypass security controls.
Are small amounts of poisoned data enough to influence a model?
Yes. Even a relatively small number of malicious samples can significantly impact machine learning performance and create hidden vulnerabilities.
Which industries are most vulnerable?
Financial services, healthcare, cybersecurity, manufacturing, autonomous systems, and e-commerce organizations are among the sectors heavily dependent on machine learning and therefore highly exposed.
Can poisoned models be repaired?
In some cases, retraining models with verified datasets can restore performance. However, identifying the contaminated data often makes recovery challenging.
How can enterprises reduce the risk of data poisoning?
Organizations should implement data validation, monitor data pipelines, maintain trusted sources, use adversarial training, and continuously evaluate model behavior to detect anomalies.